
Performance Surprises and Assumptions : DATEDIFF
It is very easy to prove that the following two expressions yield the exact same result: the first day of the current month.
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
And they take about the same amount of time to compute:
SELECT SYSDATETIME();
GO
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
GO 1000000
GO
SELECT SYSDATETIME();
GO
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
GO 1000000
SELECT SYSDATETIME();
On my system, both batches took about 175 seconds to complete.
So, why would you prefer one method over the other? When one of them really messes with cardinality estimations.
As a quick primer, let's compare these two values:
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped
(Note that the actual values represented here will change, depending on when you are reading this post – "today" referenced in the comment is September 5, 2013, the day this post was written. In October 2013, for example, the output will be 2013-10-01 and 1786-04-01.)
With that out of the way, let me show you what I mean…
A repro
Let's create a very simple table, with only a clustered DATE column, and load 15,000 rows with the value 1786-05-01 and 50 rows with the value 2013-09-01:
CREATE TABLE dbo.DateTest
(
CreateDate DATE
);
CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate);
INSERT dbo.DateTest(CreateDate)
SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0)
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
UNION ALL
SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0)
FROM sys.all_objects;
And then let's look at the actual plans for these two queries:
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
The graphical plans look right:
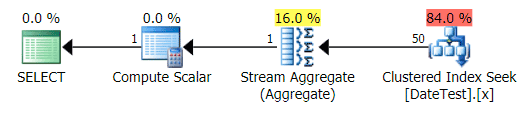
Graphical plan for DATEDIFF(MONTH, 0, GETDATE()) query
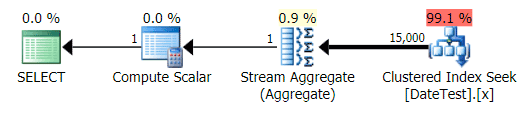
Graphical plan for DATEDIFF(MONTH, GETDATE(), 0) query
But the estimated costs are out of whack – note how much higher the estimated costs are for the first query, which only returns 50 rows, compared to the second query, which returns 15,000 rows!

Statement grid showing estimated costs
And the Top Operations tab shows that the first query (looking for 2013-09-01) estimated that it would find 15,000 rows, when in actuality it only found 50; the second query shows the opposite: it expected to find 50 rows matching 1786-05-01, but found 15,000. Based on incorrect cardinality estimates like this, I'm sure you can imagine what kind of drastic effect this could have on more complex queries against much larger data sets.
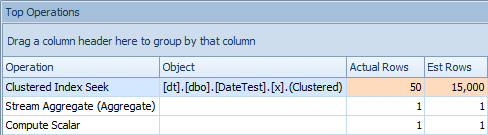
Top Operations tab for first query [DATEDIFF(MONTH, 0, GETDATE())]
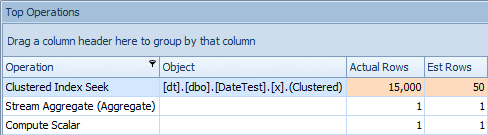
Top Operations tab for second query [DATEDIFF(MONTH, 0, GETDATE())]
A slightly different variation of the query, using a different expression to calculate the beginning of the month (alluded to at the beginning of the post), does not exhibit this symptom:
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
The plan is very similar to query 1 above, and if you didn't look closer you would think these plans are equivalent:
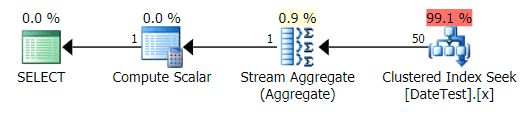
Graphical plan for non-DATEDIFF query
When you look at the Top Operations tab here, though, you see that the estimate is bang on:
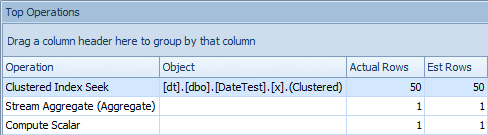
Top Operations tab showing accurate estimates
On this particular data size and query, the net performance impact (most notably duration and reads) is largely irrelevant. And it is important to note that the queries themselves still return correct data; it is just that the estimates that are wrong (and could lead to a worse plan than I've demonstrated here). That said, if you are deriving constants using DATEDIFF within your queries this way, you really should test this impact in your environment.
So why does this happen?
To put it simply, SQL Server has a DATEDIFF bug where it swaps the second and third arguments when evaluating the expression for cardinality estimation. This appears to involve constant folding, at least peripherally; there are a lot more details on constant folding in this Books Online article but, unfortunately, the article does not reveal any information about this particular bug.
There is a fix – or is there?
There is a knowledge base article (KB #2481274) that claims to address the problem, but it has a few problems of its own:
- The KB article claims that the issue has been fixed in various service packs or cumulative updates for SQL Server 2005, 2008 and 2008 R2. However, the symptom is still present in branches that aren't explicitly mentioned there, even though they have seen many additional CUs since the article was published. I can still reproduce this issue on SQL Server 2008 SP3 CU #8 (10.0.5828) and SQL Server 2012 SP1 CU #5 (11.0.3373).
- It neglects to mention that, in order to benefit from the fix, you need to turn on trace flag 4199 (and "benefit" from all of the other ways that specific trace flag can affect the optimizer). The fact that this trace flag is required for the fix is mentioned in a related Connect item, #630583, but this information hasn't made it back to the KB article. Neither the KB article nor the Connect item give any insight into the cause (that the arguments to
DATEDIFFhave been swapped during evaluation). On the plus side, running the above queries with the trace flag on (usingOPTION (QUERYTRACEON 4199)) yields plans that do not have the incorrect estimate issue.
- It suggests you use dynamic SQL to work around the issue. In my tests, using a different expression (such as the one above that doesn't use
DATEDIFF) overcame the issue in modern builds of both SQL Server 2008 and SQL Server 2012. Recommending dynamic SQL here is unnecessarily complex and probably overkill, given that a different expression could solve the problem. But if you were to use dynamic SQL, I would do it this way instead of the way they recommend in the KB article, most importantly to minimize SQL injection risks:DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;(And you can add
OPTION (RECOMPILE)there, depending on how you want SQL Server to handle parameter sniffing.)This leads to the same plan as the earlier query that doesn't use
DATEDIFF, with proper estimates and 99.1% of the cost in the clustered index seek.Another approach that might tempt you (and by you, I mean me, when I first started investigating) is to use a variable to calculate the value beforehand:
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
The problem with this approach is that, with a variable, you are going to end up with a stable plan, but the cardinality is going to be based on a guess (and the type of guess will depend on the presence or absence of statistics). In this case, here are the estimated vs. actual:
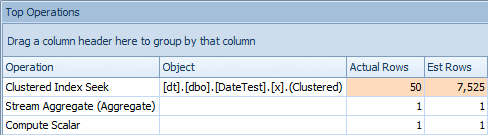
Top Operations tab for query that uses a variableThis is clearly not right; it seems SQL Server has guessed that the variable would match 50% of the rows in the table.
SQL Server 2014
I found a slightly different issue in SQL Server 2014. The first two queries are fixed (by changes to the cardinality estimator or other fixes), meaning that the DATEDIFF arguments are no longer switched. Yay!
However, a regression seems to have been introduced to the workaround of using a different expression – now it suffers from an inaccurate estimate (based on the same 50% guess as using a variable). These are the queries I ran:
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date;
Here is the statement grid comparing the estimated costs and actual runtime metrics:
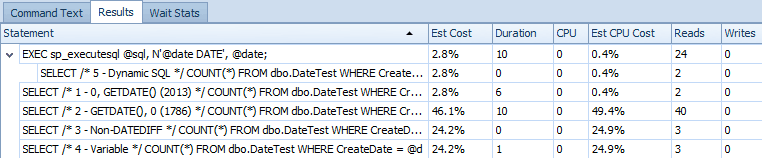
Estimated costs for the 5 specimen queries on SQL Server 2014
And these are their estimated and actual row counts (assembled using Photoshop):

Estimated and actual row counts for the 5 queries on SQL Server 2014
It is clear from this output that the expression that previously solved the issue has now introduced a different one. I am not sure if this is a symptom of running in a CTP (e.g. something that will be fixed) or if this truly is a regression.
In this case, trace flag 4199 (on its own) has no effect; the new cardinality estimator is making guesses and simply isn't correct. Whether it leads to an actual performance issue depends a lot on many other factors beyond the scope of this post.
If you come across this issue, you can – at least in current CTPs – restore the old behavior using OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199). Trace flag 9481 disables the new cardinality estimator, as described in these release notes (which will certainly disappear or at least move at some point). This in turn restores the correct estimates for the non-DATEDIFF version of the query, but unfortunately still does not solve the issue where a guess is made based on a variable (and using TF9481 alone, without TF4199, forces the first two queries to regress to the old argument-swapping behavior).
Conclusion
I will admit this was a huge surprise to me. Kudos to Martin Smith and t-clausen.dk for persevering and convincing me that this was a real and not an imagined issue. Also a big thanks to Paul White (@SQL_Kiwi) who helped me keep my sanity and reminded me of the things I shouldn't say. :-)
Being unaware of this bug, I was adamant that the better query plan was generated simply by changing the query text at all, not due to the specific change. As it turns out, sometimes a change to a query that you would assume will make no difference, actually will. So I recommend that if you have any similar query patterns in your environment, you test them and make sure cardinality estimates are coming out right. And make a note to test them again when you upgrade.
3 thoughts on “Performance Surprises and Assumptions : DATEDIFF”
Comments are closed.

Hi Aaron, thank for the observation, that’s interesting.
Here is one bug with isdate function (using table from your example).
The same thing is with isnumeric.
Erland also filed another CE bug involving DATEADD function.
It seems that estimating cardinality when intrinsic function is involved might be thin place.
Is this bug still present in SQL Server 2016?
I have tested on SQL Server 2017 and the symptom is no longer present there, but I do not know exactly when it was fixed. I could only find KB #2481274, which seems related, but is only relevant to out-of-support versions.