
Generate a set or sequence without loops – part 1
There are many use cases for generating a sequence of values in SQL Server. I'm not talking about a persisted IDENTITY column (or the new SEQUENCE in SQL Server 2012), but rather a transient set to be used only for the lifetime of a query. Or even the simplest cases – such as just appending a row number to each row in a resultset – which might involve adding a ROW_NUMBER() function to the query (or, better yet, in the presentation tier, which has to loop through the results row-by-row anyway).
I'm talking about slightly more complicated cases. For example, you may have a report that shows sales by date. A typical query might be:
SELECT
OrderDate = CONVERT(DATE, OrderDate),
OrderCount = COUNT(*)
FROM dbo.Orders
GROUP BY CONVERT(DATE, OrderDate)
ORDER BY OrderDate;
The problem with this query is that, if there are no orders on a certain day, there will be no row for that day. This can lead to confusion, misleading data, or even incorrect calculations (think daily averages) for the downstream consumers of the data.
So there is a need to fill those gaps with the dates that are not present in the data. And sometimes people will stuff their data into a #temp table and use a WHILE loop or a cursor to fill in the missing dates one-by-one. I won't show that code here because I don't want to advocate its use, but I've seen it all over the place.
Before we get too deep into dates, though, let's first talk about numbers, since you can always use a sequence of numbers to derive a sequence of dates.
Numbers table
I've long been an advocate of storing an auxiliary "numbers table" on disk (and, for that matter, a calendar table as well).
Here is one way to generate a simple numbers table with 1,000,000 values:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id]))
INTO dbo.Numbers
FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2
OPTION (MAXDOP 1);
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n)
-- WITH (DATA_COMPRESSION = PAGE)
;
Why MAXDOP 1? See Paul White's blog post and his Connect item relating to row goals.
However, many people are opposed to the auxiliary table approach. Their argument: why store all that data on disk (and in memory) when they can generate the data on-the-fly? My counter is to be realistic and think about what you're optimizing; computation can be expensive, and are you sure that calculating a range of numbers on the fly is always going to be cheaper? As far as space, the Numbers table only takes up about 11 MB compressed, and 17 MB uncompressed. And if the table is referenced frequently enough, it should always be in memory, making access fast.
Let's take a look at a few examples, and some of the more common approaches used to satisfy them. I hope we can all agree that, even at 1,000 values, we don't want to solve these problems using a loop or a cursor.
Generating a sequence of 1,000 numbers
Starting simple, let's generate a set of numbers from 1 through 1,000.
Numbers table
Of course with a numbers table this task is pretty simple:
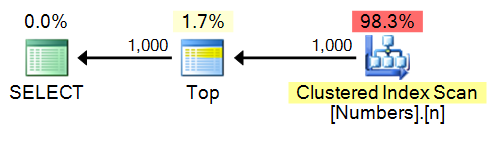
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Plan:
spt_values
This is a table that is used by internal stored procedures for various purposes. Its use online seems to be quite prevalent, even though it is undocumented, unsupported, it may disappear one day, and because it only contains a finite, non-unique, and non-contiguous set of values. There are 2,164 unique and 2,508 total values in SQL Server 2008 R2; in 2012 there are 2,167 unique and 2,515 total. This includes duplicates, negative values, and even if using DISTINCT, plenty of gaps once you get beyond the number 2,048. So the workaround is to use ROW_NUMBER() to generate a contiguous sequence, starting at 1, based on the values in the table.
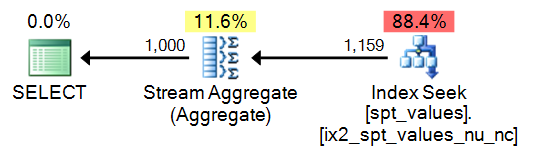
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number)
FROM [master]..spt_values ORDER BY n;
Plan:

That said, for only 1,000 values, you could write a slightly simpler query to generate the same sequence:
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
This leads to a simpler plan, of course, but breaks down pretty quickly (once your sequence has to be more than 2,048 rows):
In any case, I do not recommend the use of this table; I'm including it for comparison purposes, only because I know how much of this is out there, and how tempting it might be to just re-use code you come across.
sys.all_objects
Another approach that has been one of my favorites over the years is to use sys.all_objects. Like spt_values, there is no reliable way to generate a contiguous sequence directly, and we have the same issues dealing with a finite set (just under 2,000 rows in SQL Server 2008 R2, and just over 2,000 rows in SQL Server 2012), but for 1,000 rows we can use the same ROW_NUMBER() trick. The reason I like this approach is that (a) there is less concern that this view will disappear anytime soon, (b) the view itself is documented and supported, and (c) it will run on any database on any version since SQL Server 2005 without having to cross database boundaries (including contained databases).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Plan:

Stacked CTEs
I believe Itzik Ben-Gan deserves the ultimate credit for this approach; basically you construct a CTE with a small set of values, then you create the Cartesian product against itself in order to generate the number of rows you need. And again, instead of trying to generate a contiguous set as part of the underlying query, we can just apply ROW_NUMBER() to the final result.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n;
Plan:
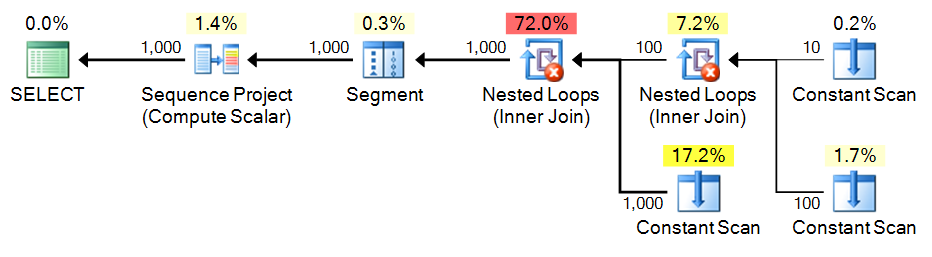
Recursive CTE
Finally, we have a recursive CTE, which uses 1 as the anchor, and adds 1 until we hit the maximum. For safety I specify the maximum in both the WHERE clause of the recursive portion, and in the MAXRECURSION setting. Depending on how many numbers you need, you may have to set MAXRECURSION to 0.
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000);
Plan:
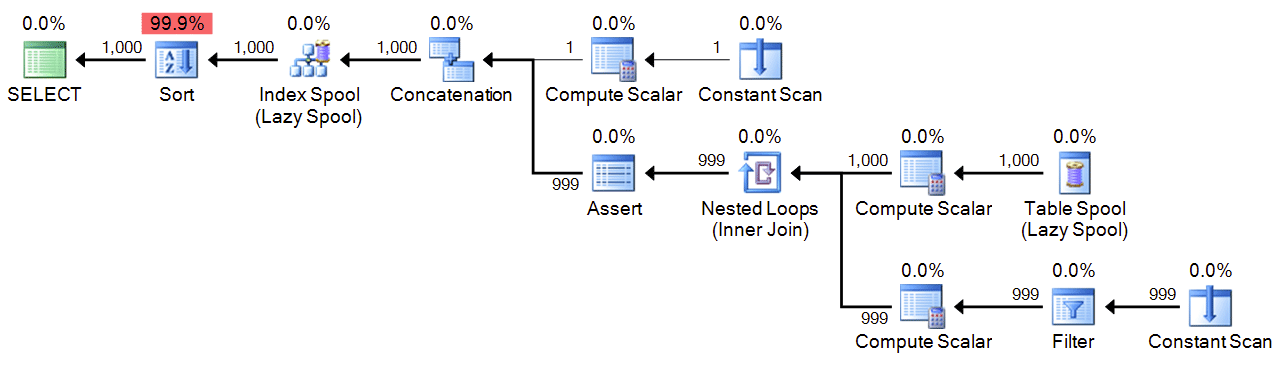
Performance
Of course with 1,000 values the differences in performance is negligible, but it can be useful to see how these different options perform:
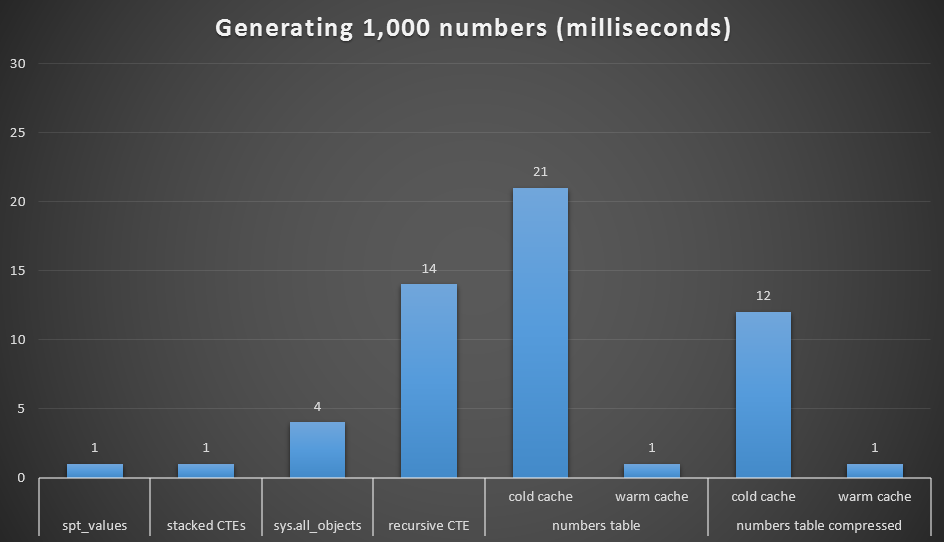
Runtime, in milliseconds, to generate 1,000 contiguous numbers
I ran each query 20 times and took average runtimes. I also tested the dbo.Numbers table, in both compressed and uncompressed formats, and with both a cold cache and a warm cache. With a warm cache it very closely rivals the other fastest options out there (spt_values, not recommended, and stacked CTEs), but the first hit is relatively expensive (though I almost laugh calling it that).
To Be Continued...
If this is your typical use case, and you won't venture far beyond 1,000 rows, then I hope I have shown the fastest ways to generate those numbers. If your use case is a larger number, or if you are looking for solutions to generate sequences of dates, stay tuned. Later in this series, I will explore generating sequences of 50,000 and 1,000,000 numbers, and of date ranges ranging from a week to a year.
14 thoughts on “Generate a set or sequence without loops – part 1”
Comments are closed.

We have a commercial product called 'XLeratorDB' that has functions for generating series, that is extremely fast and efficient. It is based on SQL-CLR. It can be used for numeric (float, int) and date series, and outputs a TVF. The series can generate linear or random results, and can be configured a few different ways (step value, start value, #iterations, end value, etc.) The functions are named 'SeriesInt', 'SeriesFloat', and 'SeriesDate'
Sorry for the spam, but it seemed very relevant to the topic. I'd be very interested to see how it compared in your chart.
Row_number is causing the type of column n to be bigint and thus the size of the table is quite big it is around 2100 pages without compression but with type of column n as int it will be 1600 pages.
Also if we will use a lot of top 1000 then why not have a filtered index where n <=1000 the size of index will be 2 pages and thus it should run in 100's of microseconds.
It's actually not a
bigint, though the code above implied that it was. I had created two tables manually (withintcolumns) which I then populated from this initialNumberstable, and those tables were used in all of the tests in these articles. Here is the table definition:And here is the page count / row count from partition stats:
Sorry about the confusion. I've updated the code above to reflect the actual data types.
I don't believe the filtered index will help, even if you do have a case where you're using the exact same set of numbers most of the time (otherwise would you create a filtered index for all of the popular sets?). After all, you already have a clustered index on that column, so SQL Server is already perfectly capable of eliminating the pages that won't be needed to satisfy a range query.
Currently if you ask for the top 1000 numbers it's going to perform a range scan on the clustered index. If you add a filtered index to the table, you'll see that the plan will still select a range scan on the clustered index. If you force the filtered index with an index hint, it will do a range scan on the filtered index, but this will end up being much more expensive (at least according to plan comparisons in Plan Explorer). Even though there is one less page read, the filtered index estimates that the whole table will be read, rather than just the 1,000 rows. In real life this doesn't seem to make much difference, but the point is that the filtered index is not selected automatically and, even if it were, provides no performance benefit.
Feel free to try this and let me know if you discover any performance gain that I wasn't able to…
Thanks for the article Aaron! I'm generating a numbers table instead of using a table function, based on this information.
Thanks Joesph, fixed, sorry about that!
Hi,
I was looking for a way to genarate a sequence of float values with equal increments where I know the minimum, maximum and increment of the float sequnce. Using one of the methods above and I little enhancment I found a solution that I would like to share with others:
SET NOCOUNT ON GO IF EXISTS ( SELECT * FROM sys.objects so WHERE so.type = 'TF' AND SCHEMA_NAME(so.schema_id) = 'dbo' AND so.name = 'F_GenarateFloatSequence' ) DROP FUNCTION [dbo].[F_GenarateFloatSequence] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE FUNCTION [dbo].[F_GenarateFloatSequence] ( @firstValue float , @lastValue float , @increment float ) RETURNS @floatSequenceTable TABLE ( SequenceIndex int , Value float ) AS BEGIN DECLARE @minValue float --DECLARE @maxValue float DECLARE @incrementFactoredOut float = @increment DECLARE @factor float DECLARE @range float DECLARE @isForwards bit -- first check the sequence direction and set the variables as needed IF @firstValue 0 BEGIN -- move to the next factor SET @factor = @factor * 10 -- calculate the result of factoring out the increment for the next loop cycle SET @incrementFactoredOut = @increment * @factor END -- update all the values needed in the select by the factor -- so that we are working with integers and an factored up range SET @increment = @increment * @factor SET @range = @range * @factor -- the following IF and ELSE are the same except the order by in the Insert select statement IF @isForwards = 1 BEGIN -- use the Recursive CTE algorithm to create a sequence with factored out step size over the range ;WITH n(n) AS ( SELECT 1 UNION ALL SELECT (n) + CAST(@increment AS INT) FROM n WHERE n >= @range ) -- insert the values into the return table taking into account the factor -- and the use minimum of the sequence to offset the values INSERT INTO @floatSequenceTable(SequenceIndex, Value) SELECT ROW_NUMBER() OVER(ORDER BY n) , ((n-1)/@factor) + @minValue FROM n -- use acsending order by as the sequnce is forwards (@fistValue < @lastValue) ORDER BY n DESC OPTION (MAXRECURSION 5000); END ELSE BEGIN -- use the Recursive CTE algorithm to create a sequence with factored out step size over the range ;WITH n(n) AS ( SELECT 1 UNION ALL SELECT (n) + CAST(@increment AS INT) FROM n WHERE n <= @lastValue) ORDER BY n DESC OPTION (MAXRECURSION 5000); END RETURN END GO -- using IF 1=0 and IF 1=1 I can turn my testing on and off in the same script, -- without losing any intelisense or syntax / compiler checking etc. IF 1=1 BEGIN -- test the sequence genaration DECLARE @testName nvarchar(255) DECLARE @firstValue float DECLARE @lastValue float DECLARE @Increment float -- Note: using a table to define the tests cases makes it quick and easy -- to test a table function by using cross apply -- other functions can also be tested using select inline function calls -- or a CURSOR using the same tast plan table technique to execute them DECLARE @testPlanTab TABLE ( TestId int identity(1,1) , TestName nvarchar(255) , FirstValue float , LastValue float , Increment float ) INSERT INTO @testPlanTab(TestName, FirstValue, LastValue, Increment) VALUES ('Both negative forwards', -4, -2, 0.5) INSERT INTO @testPlanTab(TestName, FirstValue, LastValue, Increment) VALUES ('Both negative reversed', -2, -4, 0.5) INSERT INTO @testPlanTab(TestName, FirstValue, LastValue, Increment) VALUES ('Both negative identical', -2, -2, 0.5) INSERT INTO @testPlanTab(TestName, FirstValue, LastValue, Increment) VALUES ('Both positive forwards', 2, 4, 0.5) INSERT INTO @testPlanTab(TestName, FirstValue, LastValue, Increment) VALUES ('Both positive reversed', 4, 2, 0.5) INSERT INTO @testPlanTab(TestName, FirstValue, LastValue, Increment) VALUES ('Both positive identical', 2, 2, 0.5) INSERT INTO @testPlanTab(TestName, FirstValue, LastValue, Increment) VALUES ('Both zero ', 0, 0, 0.5) INSERT INTO @testPlanTab(TestName, FirstValue, LastValue, Increment) VALUES ('First negative last positive', -1, 1, 0.5) INSERT INTO @testPlanTab(TestName, FirstValue, LastValue, Increment) VALUES ('First positive last negative', 1, -1, 0.5) SELECT 'Test case ' + CAST(t.TestId AS nvarchar(10)) + ': ' + t.TestName + ' (' + CAST(t.FirstValue AS nvarchar(10)) + ', ' + CAST(t.LastValue AS nvarchar(10)) + ')' AS TestDescription , f.SequenceIndex , f.Value FROM @testPlanTab t CROSS APPLY [dbo].[F_GenarateFloatSequence] (t.FirstValue, t.LastValue, t.Increment) f ORDER BY t.TestId, f.SequenceIndex ENDHi Guy, not all of the syntax came across right (some comparison operators are missing, I guessed in one place but then realized that may be wrong, then spotted others too). Let me know if you can take a look and I'll correct it.
(Also, curious that you chose a recursive CTE approach; the slowest method above.)
It's so funny that the SQL Server team now has a compatibility burden to never decrease the number of rows in spt_values.
Very nice comparison. I added some readability improvement to the stacked CTE (at least for me) :
;WITH e1(n) AS
(
select 1 from (values (1),(2),(3),(4),(5),(6),(7),(8),(9),(0)) t(n)
)
SELECT ROW_NUMBER() OVER (ORDER BY n10.n) AS n
FROM
e1 n10
CROSS JOIN e1 n100
CROSS JOIN e1 n1000
CROSS JOIN e1 n10000
CROSS JOIN e1 n100000
CROSS JOIN e1 n1000000
The execution plan is actually all the same.