
Ten Common Threats to Execution Plan Quality
The quality of an execution plan is highly dependent on the accuracy of the estimated number of rows output by each plan operator. If the estimated number of rows is significantly skewed from the actual number of rows, this can have a significant impact on the quality of a query's execution plan. Poor plan quality can be responsible for excessive I/O, inflated CPU, memory pressure, decreased throughput and reduced overall concurrency.
By "plan quality" – I'm talking about having SQL Server generate an execution plan that results in physical operator choices that reflect the current state of the data. By making such decisions based on accurate data, there is a better chance that the query will perform properly. The cardinality estimate values are used as input for operator costing, and when the values are too far off from reality, the negative impact to the execution plan can be pronounced. These estimates are fed to the various cost models associated to the query itself, and bad row estimates can impact a variety of decisions including index selection, seek vs. scan operations, parallel versus serial execution, join algorithm selection, inner vs. outer physical join selection (e.g. build vs. probe), spool generation, bookmark lookups vs. full clustered or heap table access, stream or hash aggregate selection, and whether or not a data modification uses a wide or narrow plan.
As an example, let's say you have the following SELECT query (using the Credit database):
SELECT
m.member_no,
m.lastname,
p.payment_no,
p.payment_dt,
p.payment_amt
FROM dbo.member AS m
INNER JOIN dbo.payment AS p
ON m.member_no = p.member_no;
Based on the query logic, is the following plan shape what you would expect to see?
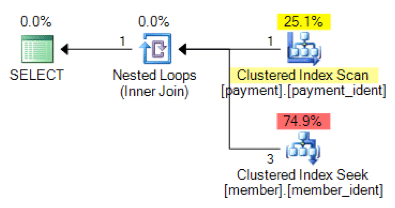
And what about this alternative plan, where instead of a nested loop we have a hash match?
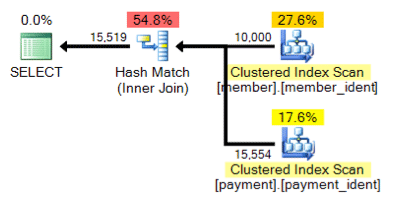
The "correct" answer is dependent on a few other factors – but one major factor is the number of rows in each of the tables. In some cases, one physical join algorithm is more appropriate than the other – and if the initial cardinality estimate assumptions aren't correct, your query may be using a non-optimal approach.
Identifying cardinality estimate issues is relatively straightforward. If you have an actual execution plan, you can compare the estimated versus actual row count values for operators and look for skews. SQL Sentry Plan Explorer simplifies this task by allowing you to see actual versus estimated rows for all operators in a single plan tree tab versus having to hover over the individual operators in the graphical plan:

Now, skews don't always result in poor quality plans, but if you are having performance issues with a query and you see such skews in the plan, this is one area that is then worthy of further investigation.
Identification of cardinality estimate issues is relatively straightforward, but the resolution often isn't. There are a number of root causes as to why cardinality estimate issues can occur, and I'll cover ten of the more common reasons in this post.
Missing or Stale Statistics
Of all the reasons for cardinality estimate issues, this is the one that you hope to see, as it is often easiest to address. In this scenario, your statistics are either missing or out-of-date. You may have database options for automatic statistics creation and updates disabled, "no recomputed" enabled for specific statistics, or have large enough tables that your automatic statistics updates simply aren't happening frequently enough.
Sampling Issues
It may be that the precision of the statistics histogram is inadequate – for example, if you have a very large table with significant and/or frequent data skews. You may need to change your sampling from the default or if even that doesn't help – investigate using separate tables, filtered statistics or filtered indexes.
Hidden Column Correlations
The query optimizer assumes that columns within the same table are independent. For example, if you have a city and state column, we may intuitively know that these two columns are correlated, but SQL Server does not understand this unless we help it out with an associated multi-column index, or with manually-created multi-column statistics. Without helping the optimizer with correlation, the selectivity of your predicates may be exaggerated.
Below is an example of two correlated predicates:
SELECT
lastname,
firstname
FROM dbo.member
WHERE city = 'Minneapolis'
AND state_prov - 'MN';
I happen to know that 10% of our 10,000 row member table qualify for this combination, but the query optimizer is guessing that it is 1% of the 10,000 rows:
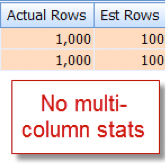
Now contrast this with the appropriate estimate that I see after adding multi-column statistics:
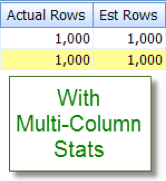
Intra-Table Column Comparisons
Cardinality estimation issues can occur when comparing columns within the same table. This is a known issue. If you have to do so, you can improve the cardinality estimates of the column comparisons by using computed columns instead or by re-writing the query to use self-joins or common table expressions.
Table Variable Usage
Using table variables much? Table variables show a cardinality estimate of "1" – which for just a small number of rows may not be an issue, but for large or volatile result sets can significantly impact query plan quality. Below is a screenshot of an operator's estimate of 1 row versus the actual 1,600,000 rows from the @charge table variable:

If this is your root cause, you would be well-advised to explore alternatives like temporary tables and or permanent staging tables where possible.
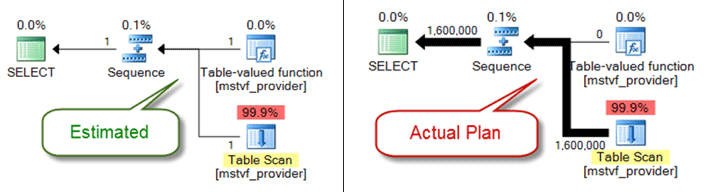
Scalar and MSTV UDFs
Similar to table variables, multi-statement table-valued and scalar functions are a black-box from a cardinality estimation perspective. If you're encountering plan quality issues due to them, consider inline table functions as an alternative – or even pulling out the function reference entirely and just referencing objects directly.
Below shows an estimated versus actual plan when using a multi-statement table-valued function:
Data Type Issues
Implicit data type issues in conjunction with search and join conditions can cause cardinality estimate issues. They also can also surreptitiously eat away at server-level resources (CPU, I/O, memory), so it's important to address them whenever possible.
Complex Predicates
You’ve probably seen this pattern before – a query with a WHERE clause that has each table column reference wrapped in various functions, concatenation operations, mathematical operations and more. And while not all function wrapping precludes proper cardinality estimates (such as for LOWER, UPPER and GETDATE) there are plenty of ways to bury your predicate to the point that the query optimizer can no longer make accurate estimates.
Query Complexity
Similar to buried predicates, are your queries extraordinarily complex? I realize “complex” is a subjective term, and your assessment may vary, but most can agree that nesting views within views within views that reference overlapping tables is likely to be non-optimal – especially when coupled with 10+ table joins, function references and buried predicates. While the query optimizer does an admirable job, it isn’t magic, and if you have significant skews, query complexity (Swiss-army knife queries) can certainly make it next to impossible to derive accurate row estimates for operators.
Distributed Queries
Are you using distributed queries with linked servers and you see significant cardinality estimate issues? If so, be sure to check the permissions associated with the linked server principal being used to access the data. Without the minimum db_ddladmin fixed database role for the linked server account, this lack of visibility to remote statistics due to insufficient permissions may be the source for your cardinality estimation issues.
And there are others…
There are other reasons why cardinality estimates can be skewed, but I believe I've covered the most common ones. The key point is to pay attention to the skews in association with known, poorly performing queries. Don't assume that the plan was generated based on accurate row count conditions. If these numbers are skewed, you need to try to troubleshoot this first.
11 thoughts on “Ten Common Threats to Execution Plan Quality”
Comments are closed.

Hi Joe,
thank you very much for your great article.
I would like to ask you or anybody about the question related to execution plan quality. Why does SQL Optimizer ignore variables (with static values) during building execution plan?
Let's have this example:
When I add a recompile hint in the first point, there will be the same execution plan as in the second point.
Thank you very much for any comment.
Very good article Joe. I've been dealing with these exact issues. Thanks!
Jan and Tom, thanks for the feedback!
Jan – I'm boarding a plane and heading off on vacation until Monday. But I'll reply to your question upon return.
Cheers!
Jan,
This seems like a common parameter sniffing issue to me – the compiled version of the first plan has a different parameter than the one you're using (or no parameter value at all). For example, is it possible that you ran the same query previously with an earlier date, which would have yielded a much larger percentage of the table, meaning that an index scan would actually be more efficient than a loop join and a series of seeks?
You can see the parameter that is stored with the cached version of the plan by poring over the ShowPlan XML or by generating an actual plan in SQL Sentry Plan Explorer and looking at the Parameters tab. You can also see that distribution is not quite even in the
SalesOrderHeadertable – most of the data is weighted toward the most recent dates, making it hard for SQL Server to accurately guess which plan shape will be most efficient.You can work around this by using
RECOMPILE, as you've identified, but I would try putting it into a stored procedure first. If you're using a stored procedure and still seeing this issue, you can continue to useRECOMPILE(at the procedure or statement level), but there are other workarounds as well – e.g.:OPTIMIZE FOR;Some other articles on parameter sniffing:
http://blogs.technet.com/b/mdegre/archive/2012/03/19/what-is-parameter-sniffing.aspx
http://blogs.msdn.com/b/queryoptteam/archive/2006/03/31/565991.aspx
http://www.sqlpointers.com/2006/11/parameter-sniffing-stored-procedures.html
Aaron,
thank you so much for your detailed answer!
I have also tried your suggestions and they worked great. I must also read the articles about parameter sniffing you posted.
I used dbcc freeproccache and the only value '20040731' was in variable for column OrderDate.
I have played with it and I have found that Actual execution plan for point 1 shows only one statement (in XML) in plan. But if I looked into cache:
And opened the cached execution plan with SQL Sentry Plan Explorer, I saw two statements (<StmtSimple>) in plan:
http://www.mujstart.cz/temp/image_05.jpg
If I understand it correctly, SQL Server is not able to optimize execution plan for the query, when the variable has its own <StmtSimple>.
In brackets and in the last sentence a word StmtSimple is missing. I wrote it in tags, but it disappeared. :(
The two statements in the plan are expected. But I suggest you copy the query into Plan Explorer and generate an actual execution plan directly – you will have access to more data that isn't included when you pull the plan XML from the cache.
Jan,
It is possible that "parameter sniffing" is causing the behaviour you are seeing, but I would like to comment that SQL Server uses different approach to estimate cardinality when we use a constant, a parameter, or a variable as part of the predicate. The main different is that SQL Server is not aware of the value in the variable by the time it compiles the statement, using a rough estimate of 30 percent of the number of rows for non-equality comparisons, or using the "All Density" value from the statistics related to the columns in the expression for equality comparisons, instead using the histogram.
If you use OPTION (RECOMPILE) then SQL Server will be aware of the value in the variable when the execution get to the statement and recompiles it.
You can read more about this from this great white paper.
Statistics Used by the Query Optimizer in Microsoft SQL Server 2005
http://technet.microsoft.com/en-us/library/cc966419.aspx
Statistics Used by the Query Optimizer in Microsoft SQL Server 2008
http://msdn.microsoft.com/en-us/library/dd535534(v=SQL.100).aspx
—
AMB
Hi Joe,
The Credit sample database at the link you gave contains blanks for
cityandstate_provin the member table. Do you have a link to a version of the database that contains the data you used? I was looking to run the script shown in the "Hidden Column Correlations" section.Cheers,
Paul
Hi Paul,
Sure – here is the prep script and then a bit more (showing how invalid city/state combos can remove some of the virtue of multi-column stats / idxs):
USE [Credit];
GO
UPDATE [dbo].[member]
SET [city] = 'Minneapolis',
[state_prov] = 'MN'
WHERE [member_no] % 10 = 0;
UPDATE [dbo].[member]
SET [city] = 'New York',
[state_prov] = 'NY'
WHERE [member_no] % 10 = 1;
UPDATE [dbo].[member]
SET [city] = 'Chicago',
[state_prov] = 'IL'
WHERE [member_no] % 10 = 2;
UPDATE [dbo].[member]
SET [city] = 'Houston',
[state_prov] = 'TX'
WHERE [member_no] % 10 = 3;
UPDATE [dbo].[member]
SET [city] = 'Philadelphia',
[state_prov] = 'PA'
WHERE [member_no] % 10 = 4;
UPDATE [dbo].[member]
SET [city] = 'Phoenix',
[state_prov] = 'AZ'
WHERE [member_no] % 10 = 5;
UPDATE [dbo].[member]
SET [city] = 'San Antonio',
[state_prov] = 'TX'
WHERE [member_no] % 10 = 6;
UPDATE [dbo].[member]
SET [city] = 'San Diego',
[state_prov] = 'CA'
WHERE [member_no] % 10 = 7;
UPDATE [dbo].[member]
SET [city] = 'Dallas',
[state_prov] = 'TX'
WHERE [member_no] % 10 = 8;
GO
-- Estimation with just Minneapolis?
SELECT [lastname],
[firstname]
FROM [dbo].[member]
WHERE [city] = 'Minneapolis';
GO
-- What statistics exist for the table at this point?
EXEC dbo.sp_helpstats 'member';
-- What about the statistics?
DBCC SHOW_STATISTICS('member', '_WA_Sys_00000006_0CBAE877');
-- Minneapolis and Minnesota?
SELECT [lastname],
[firstname]
FROM [dbo].[member]
WHERE [city] = 'Minneapolis' AND
[state_prov] = 'MN'
OPTION (RECOMPILE);
GO
-- What statistics exist for the table at this point?
EXEC dbo.sp_helpstats 'member';
-- What about the statistics?
DBCC SHOW_STATISTICS('member', '_WA_Sys_00000007_0CBAE877');
-- Create multi-column stats
CREATE STATISTICS [member_city_state_prov]
ON [dbo].[member]([city],[state_prov]);
GO
-- Now what is the estimate?
SELECT [lastname],
[firstname]
FROM [dbo].[member]
WHERE [city] = 'Minneapolis' AND
[state_prov] = 'MN'
OPTION (RECOMPILE);
GO
-- What about the statistics?
DBCC SHOW_STATISTICS('member', 'member_city_state_prov');
-- Now what is the estimate?
SELECT [lastname],
[firstname]
FROM [dbo].[member]
WHERE [city] = 'Minneapolis' AND
[state_prov] = 'TX'
OPTION (RECOMPILE);
GO
-- Remove stats
DROP STATISTICS [dbo].[member].[member_city_state_prov];
GO
Cheers,
Joe
Thanks for the setup script, Joe.
You anticipated the point I was going to make re: the usefulness of "multi-column" statistics.
Paul