
Minimizing the impact of DBCC CHECKDB : DOs and DON'Ts
Your responsibilities as a DBA (or <insert role here>) probably include things like performance tuning, capacity planning, and disaster recovery. What many people tend to forget or defer is ensuring the integrity of the structure of their databases (both logical and physical); the most important step being DBCC CHECKDB. You can get partway there by creating a simple maintenance plan with a "Check Database Integrity Task" – however, in my mind, this is just checking a checkbox.

If you look closer, there is very little you can do to control how the task operates. Even the quite expansive Properties panel exposes a whole lot of settings for the maintenance subplan, but virtually nothing about the DBCC commands it will run. Personally I think you should take a much more proactive and controlled approach to how you perform your CHECKDB operations in production environments, by creating your own jobs and manually hand-crafting your DBCC commands. You might tailor your schedule or the commands themselves to different databases – for example the ASP.NET membership database is probably not as crucial as your sales database, and could tolerate less frequent and/or less thorough checks.
But for your crucial databases, I thought I would put together a post to detail some of the things I would investigate in order to minimize the disruption DBCC commands may cause – and what myths and marketing hoopla you should be wary of. And I want to thank Paul "Mr. DBCC" Randal (@PaulRandal) for providing valuable input – not only to this specific post, but also the endless advice he provides on his blog, #sqlhelp and in SQLskills Immersion training.
Please take all of these ideas with a grain of salt, and do your best to perform adequate testing in your environment – not all of these suggestions will yield better performance in all environments. But you owe it to yourself, your users and your stakeholders to at least consider the impact that your CHECKDB operations might have, and take steps to mitigate those effects where feasible – without introducing unnecessary risk by not checking the right things.
Reduce the noise and consume all errors
No matter where you are running CHECKDB, always use the WITH NO_INFOMSGS option. This simply suppresses all the irrelevant output that just tells you how many rows are in each table; if you're interested in that information, you can get it from simple queries against DMVs and not while DBCC is running. Suppressing the output makes it far less likely that you'll miss a critical message buried in all that happy output.
Similarly, you should always use the WITH ALL_ERRORMSGS option, but especially if you are running SQL Server 2008 RTM or SQL Server 2005 (in those cases, you may see the list of per-object errors truncated to 200). For any CHECKDB operations other than quick ad-hoc checks, you should consider directing output to a file. Management Studio is limited to 1000 lines of output from DBCC CHECKDB, so you might miss out on some errors if you exceed this figure.
While not strictly a performance issue, using these options will prevent you from having to run the process again. This is particularly critical if you're in the middle of disaster recovery.
Offload logical checks where possible
In most cases, CHECKDB spends the majority of its time performing logical checks of the data. If you have the ability to perform these checks on a true copy of the data, you can focus your efforts on the physical structure of your production systems, and use the secondary server to handle all of the logical checks and alleviate that load from the primary. By secondary server, I mean only the following:
- The place where you test your full restores – because you test your restores, right?
Other folks (most notably the behemoth marketing force that is Microsoft) might have convinced you that other forms of secondary servers are suitable for DBCC checks. For example:
- an AlwaysOn Availability Group readable secondary;
- a snapshot of a mirrored database;
- a log shipped secondary;
- SAN mirroring;
- or other variations…
Unfortunately, this is not the case, and none of these secondaries are valid, reliable places to perform your checks as an alternative to the primary. Only a one-for-one backup can serve as a true copy; anything else that relies on things like the application of log backups to get to a consistent state is not going to reliably reflect integrity problems on the primary.
So rather than try to offload your logical checks to a secondary and never perform them on the primary, here is what I suggest:
- Make sure you are frequently testing the restores of your full backups. And no, this does not include
COPY_ONLYbackups from from an AG secondary, for the same reasons as above – that would only be valid in the case where you have just initiated the secondary with a full restore. - Run
DBCC CHECKDBoften against the full restore, before doing anything else. Again, replaying log records at this point will invalidate this database as a true copy of the source. - Run
DBCC CHECKDBagainst your primary, perhaps broken up in ways that Paul Randal suggests, and/or on a less frequent schedule, and/or usingPHYSICAL_ONLYmore often than not. This can depend on how often and reliably you are performing (2). - Never assume that checks against the secondary are enough. Even with an exact replica of your primary database, there are still physical issues that can occur on the I/O subsystem of your primary that will never propagate to the secondary.
- Always analyze
DBCCoutput. Just running it and ignoring it, to check it off some list, is as helpful as running backups and claiming success without ever testing that you can actually restore that backup when needed.
Experiment with trace flags 2549, 2562, and 2566
I've done some thorough testing of two trace flags (2549 and 2562) and have found that they can yield substantial performance improvements, however Lonny reports they are no longer necessary or useful. If you're on 2016 or newer, skip this entire section. If you're on an older version, these two trace flags are described in a lot more detail in KB #2634571, but basically:
- Trace Flag 2549
- This optimizes the checkdb process by treating each individual database file as residing on a unique underlying disk. This is okay to use if your database has a single data file, or if you know that each database file is, in fact, on a separate drive. If your database has multiple files and they share a single, direct-attached spindle, you should be wary of this trace flag, as it may do more harm than good.
IMPORTANT: sql.sasquatch reports a regression in this trace flag behavior in SQL Server 2014.
- This optimizes the checkdb process by treating each individual database file as residing on a unique underlying disk. This is okay to use if your database has a single data file, or if you know that each database file is, in fact, on a separate drive. If your database has multiple files and they share a single, direct-attached spindle, you should be wary of this trace flag, as it may do more harm than good.
- Trace Flag 2562
- This flag treats the entire checkdb process as a single batch, at the cost of higher tempdb utilization (up to 5% of the database size).
- Uses a better algorithm to determine how to read pages from the database, reducing latch contention (specifically for
DBCC_MULTIOBJECT_SCANNER). Note that this specific improvement is in the SQL Server 2012 code path, so you will benefit from it even without the trace flag. This can avoid errors such as:
Timeout occurred while waiting for latch: class 'DBCC_MULTIOBJECT_SCANNER'.
- The above two trace flags are available in the following versions:
SQL Server 2008 Service Pack 2 Cumulative Update 9+
(10.00.4330 -> 10.00.5499)SQL Server 2008 Service Pack 3 Cumulative Update 4+
(10.00.5775+)SQL Server 2008 R2 RTM Cumulative Update 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Service Pack 1 Cumulative Update 4+
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Service Pack 2
(10.50.4000+)SQL Server 2012, all versions
(11.00.2100+) - Trace Flag 2566
- If you are still using SQL Server 2005, this trace flag, introduced in 2005 SP2 CU#9 (9.00.3282) (though not documented in that Cumulative Update's Knowledge Base article, KB #953752), attempts to correct poor performance of
DATA_PURITYchecks on x64-based systems. At one point, you could see more details in KB #945770, but it seems that article was scrubbed from both Microsoft's support site and the WayBack machine. This trace flag should not be necessary in more modern versions of SQL Server, as the problem in the query processor has been fixed.
- If you are still using SQL Server 2005, this trace flag, introduced in 2005 SP2 CU#9 (9.00.3282) (though not documented in that Cumulative Update's Knowledge Base article, KB #953752), attempts to correct poor performance of
If you're going to use any of these trace flags, I highly recommend setting them at the session level using DBCC TRACEON rather than as a startup trace flag. Not only does it enable you to turn them off without having to cycle SQL Server, but it also allows you to implement them only when performing certain CHECKDB commands, as opposed to operations using any type of repair.
Reduce I/O impact: optimize tempdb
DBCC CHECKDB can make heavy use of tempdb, so make sure you plan for resource utilization there. This is usually a good thing to do in any case. For CHECKDB you'll want to properly allocate space to tempdb; the last thing you want is for CHECKDB progress (and any other concurrent operations) to have to wait for an autogrow. You can get an idea for requirements using WITH ESTIMATEONLY, as Paul explains here. Just be aware that the estimate can be quite low due to a bug in SQL Server 2008 R2. Also if you are using trace flag 2562 be sure to accommodate for the additional space requirements.
And of course, all of the typical advice for optimizing tempdb on just about any system is appropriate here as well: make sure tempdb is on its own set of fast spindles, make sure it is sized to accommodate all other concurrent activity without having to grow, make sure you are using an optimal number of data files, etc. A few other resources you might consider:
- Optimizing tempdb Performance (MSDN)
- Capacity Planning for tempdb (MSDN)
- A SQL Server DBA myth a day: (12/30) tempdb should always have one data file per processor core
Reduce I/O impact: control the snapshot
In order to run CHECKDB, modern versions of SQL Server will attempt to create a hidden snapshot of your database on the same drive (or on all of the drives if your data files span multiple drives). You can't control this mechanism, but if you want to control where CHECKDB operates, create your own snapshot first (Enterprise Edition required) on whatever drive you like, and run the DBCC command against the snapshot. In either case, you'll want to run this operation during a relative downtime, to minimize the copy-on-write activity that will go through the snapshot. And you won't want this schedule to conflict with any heavy write operations, like index maintenance or ETL.
You may have seen suggestions to force CHECKDB to run in offline mode using the WITH TABLOCK option. I strongly recommend against this approach. If your database is actively being used, choosing this option will just make users frustrated. And if the database is not actively being used, you're not saving any disk space by avoiding a snapshot, since there will be no copy-on-write activity to store.
Reduce I/O impact: avoid 665 / 1450 / 1452 errors
In some cases you may see one of the following errors:
The operating system returned error 665(The requested operation could not be completed due to a file system limitation) to SQL Server during a write at offset 0x[…] in file '[file]'
There are some tips here for reducing the risk of these errors during CHECKDB operations, and reducing their impact in general – with several fixes available, depending on your operating system and SQL Server version:
- Sparse File Errors: 1450 or 665 due to file fragmentation: Fixes and Workarounds
- SQL Server reports operating system error 1450 or 1452 or 665 (retries)
Reduce CPU impact
DBCC CHECKDB is multi-threaded by default (but only in Enterprise Edition). If your system is CPU-bound, or you just want CHECKDB to use less CPU at the cost of running longer, you can consider reducing parallelism in a couple of different ways:
- Use Resource Governor on 2008 and above, as long as you are running Enterprise Edition. To target just DBCC commands for a particular resource pool or workload group, you'll have to write a classifier function that can identify the sessions that will be performing this work (e.g. a specific login or a job_id).
- Use Trace flag 2528 to turn off parallelism for
DBCC CHECKDB(as well asCHECKFILEGROUPandCHECKTABLE). Trace flag 2528 is described here. Of course this is only valid in Enterprise Edition, because in spite of what Books Online currently says, the truth is thatCHECKDBdoes not go parallel in Standard Edition. - While the
DBCCcommand itself does not supportMAXDOP(at least prior to SQL Server 2014 SP2), it does respect the global settingmax degree of parallelism. Probably not something I would do in production unless I had no other options, but this is one overarching way to control certainDBCCcommands if you can't target them more explicitly.
We'd been asking for better control over the number of CPUs that DBCC CHECKDB uses, but they had been repeatedly denied until SQL Server 2014 SP2. So you can now add WITH MAXDOP = n to the command.
My Findings
I wanted to demonstrate a few of these techniques in an environment I could control. I installed AdventureWorks2012, then expanded it using the AW enlarger script written by Jonathan Kehayias (blog | @SQLPoolBoy), which grew the database to about 7 GB. Then I ran a series of CHECKDB commands against it, and timed them. I used a plain vanilla DBCC CHECKDB on its own, then all other commands used WITH NO_INFOMSGS, ALL_ERRORMSGS. Then four tests with (a) no trace flags, (b) 2549, (c) 2562, and (d) both 2549 and 2562. Then I repeated those four tests, but added the PHYSICAL_ONLY option, which bypasses all of the logical checks. The results (averaged over 10 test runs) are telling:
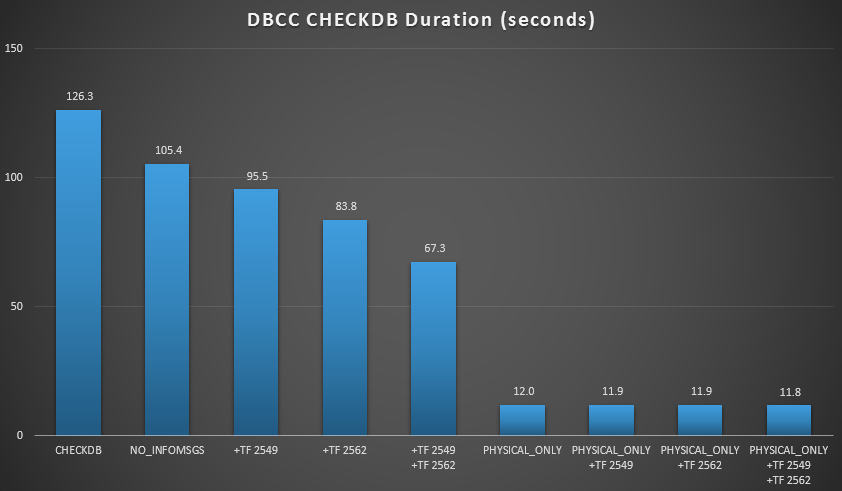
CHECKDB results against 7 GB database
Then I expanded the database some more, making many copies of the two enlarged tables, leading to a database size just north of 70 GB, and ran the tests again. The results, again averaged over 10 test runs:
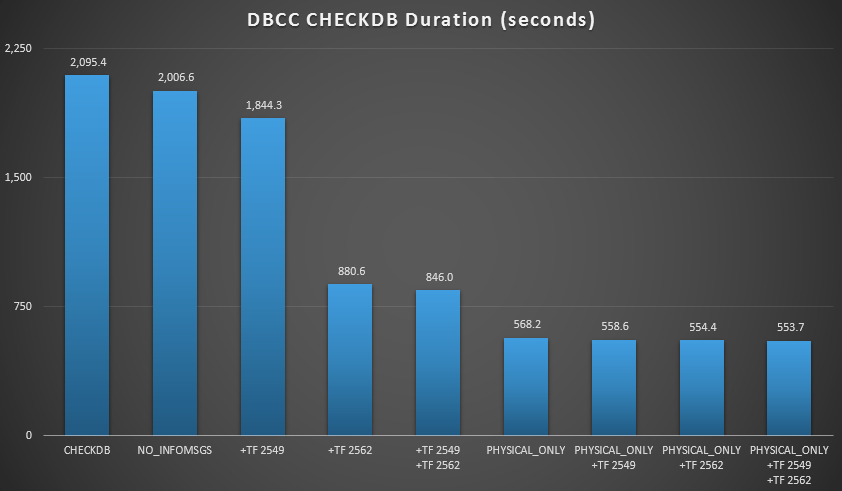
CHECKDB results against 70 GB database
In these two scenarios, I have learned the following (again, keeping in mind that your mileage may vary, and that you will need to perform your own tests to draw any meaningful conclusions):
- When I have to perform logical checks:
- At small database sizes, the
NO_INFOMSGSoption can cut processing time significantly when the checks are run in SSMS. On larger databases, however, this benefit diminishes, as the time and work spent relaying the information becomes such an insignificant portion of the overall duration. 21 seconds out of 2 minutes is substantial; 88 seconds out of 35 minutes, not so much. - The two trace flags I tested had a significant impact on performance – representing a runtime reduction of 40-60% when both were used together.
- At small database sizes, the
- When I can push logical checks to a secondary server (again, assuming that I am performing logical checks elsewhere against a true copy):
- I can reduce processing time on my primary instance by 70-90% compared to a standard
CHECKDBcall with no options. - In my scenario, the trace flags had very little impact on duration when performing
PHYSICAL_ONLYchecks.
- I can reduce processing time on my primary instance by 70-90% compared to a standard
Of course, and I can't stress this enough, these are relatively small databases and only used so that I could perform repeated, measured tests in a reasonable amount of time. This server had 80 logical CPUs and 128 GB RAM, and I was the only user. Duration and interaction with other workloads on the system may skew these results quite a bit. Here is a quick glimpse of typical CPU usage, using SQL Sentry, during one of the CHECKDB operations (and none of the options really changed the overall impact on CPU, just duration):

CPU impact during CHECKDB – sample mode
And here is another view, showing similar CPU profiles for three different sample CHECKDB operations in historical mode (I've overlaid a description of the three tests sampled in this range):

CPU impact during CHECKDB – historical mode
On even larger databases, hosted on busier servers, you may see different effects, and your mileage is quite likely to vary. So please perform your due diligence and test out these options and trace flags during a typical concurrent workload before deciding how you want to approach CHECKDB.
Conclusion
DBCC CHECKDB is a very important but often undervalued part of your responsibility as a DBA or architect, and crucial to the protection of your company's data. Do not take this responsibility lightly, and do your best to ensure that you do not sacrifice anything in the interest of reducing impact on your production instances. Most importantly: look beyond the marketing data sheets to be sure you fully understand how valid those promises are and whether you are willing to bet your company's data on them. Skimping out on some checks or offloading them to invalid secondary locations could be a disaster waiting to happen.
You should also consider reading these PSS articles:
- A faster CHECKDB – Part I
- A faster CHECKDB – Part II
- A faster CHECKDB – Part III
- A faster CHECKDB – Part IV (SQL CLR UDTs)
And this post from Brent Ozar:
Finally, if you have an unresolved question about DBCC CHECKDB, post it to the #sqlhelp hash tag on twitter. Paul checks that tag often and, since his picture should appear in the main Books Online article, it's likely that if anyone can answer it, he can. If it's too complex for 140 characters, you can ask here (and I will make sure Paul sees it at some point), or post to a forum site such as Database Administrators Stack Exchange.
27 thoughts on “Minimizing the impact of DBCC CHECKDB : DOs and DON'Ts”
Comments are closed.

Aaron,
If you look in the comments section here: http://www.sqlskills.com/blogs/paul/post/Importance-of-how-you-run-consistency-checks.aspx#comment you will see that Paul specifically addresses SAN snapshots as OK to use to run CHECKDB against because they are not continually updating copies and in most cases are presenting you the same actual physical blocks on the SAN that the DB is residing on, with the difference being only what is being stored in the snap cache.
Thanks for the article, though, you definitely hit some things that I would like to look at in my environment, where DBCC CheckDB on our largest DB can take upwards of 2 days to complete.
Thanks Joe, yes a SAN snapshot *can* be a substitute for a full backup – depending on the implementation, of course, and keeping Paul's advice about timing in mind (e.g. don't run
CHECKDBnow on a snapshot you took last week).Great post Aaron. Will experiment with those TF.
Another option would be to use third party tools that do virtual database restores reducing the time and storage space required and run the DBCC against those virtual databases.
I have a question. Are there any risks of running daily DBCC CHECKDB WITH PHYSICAL_ONLY and weekly full DBCC CHECKDB?
Damn man, don't leave anything for the rest of us to blog about. That was a seriously outstanding read through on how best to manage DBCC CHECKDB. Well done, and thanks.
Thanks Ivan.
For your first question, it really depends on what third party tools you're talking about, and how exactly they do their virtual restores.
The risks of only running logical checks once a week, obviously, is missing out on some logical corruption that happened on Sunday right after you did your DBCC against the backup Saturday night. So at that point it becomes a balance. Is that better than never running CHECKDB? Of course. But having that corruption go undetected for a week might not leave you in the best shape.
Thanks Grant!
Great post. One clarification about AlwaysOn Availability Groups, though – the primary might actually be the *wrong* place to run DBCC:
http://www.brentozar.com/archive/2012/02/where-run-dbcc-on-alwayson-availability-groups/
Helpful tips!! My database got corrupted & one user suggested me dbcc checkdb repair_allow_data_loss command to repair database But I want to know in which case, I should use dbcc checkdb repair_allow_data_loss command.
Great post!
Thanks for sharing
Warning with REPAIR_ALLOW_DATA_LOSS. Last resort.
http://technet.microsoft.com/es-es/library/ms176064.aspx
I copy :
"Use the REPAIR options only as a last resort. To repair errors, we recommend restoring from a backup. Repair operations do not consider any of the constraints that may exist on or between tables. If the specified table is involved in one or more constraints, we recommend running DBCC CHECKCONSTRAINTS after a repair operation. If you must use REPAIR, run DBCC CHECKDB without a repair option to find the repair level to use. If you use the REPAIR_ALLOW_DATA_LOSS level, we recommend that you back up the database before you run DBCC CHECKDB with this option."
Hey Prett,
You should NEVER use dbcc checkdb repair_allow_data_loss unless it is your last and final option. The only reason i would ever use it is if i did not have any valid backups at all, in that case i would be up a certain creek without a paddle, and repair_allow_data_loss would be my only option.
The best you can hope for in a corruption issue is having a valid backup chain to restore from. If you do and its just a few pages that are having troubles and you are using the enterprise edition of 2005 or higher, would be an online page restore. If that is not possible because of not being at the enterprise level, than an offline restore would have to take place.
Cheers,
if all of your environments are the same, than you could do many different things to test your backups. Restore each and every database in your production environment to a test environment once a week, and run a dbcc checkdb on the restored copies in a test environment. This is probably the best possible scenario you could look for. In terms of setup, yes it would be alot of work. But you'd thank yourself in the long run. Overall this was an awesome topic, Brent and Paul are amazing at what they do! Keep up the awesome work guys!
Its in your best interest to learn powershell, it has so many advantages to allow a DBA to automate these types of tasks.
Cheers,
Look at the object_name(id) of the object that is corrupted, hopefully it is a non clustered index, drop it and re-create it, I got by this way a few times, but luckily of was non clustered indexes that were broken.
Look at the object_name(id) of the object that is corrupted, hopefully it is a non clustered index, drop it and re-create it, I got by this way a few times, but luckily of was non clustered indexes that were broken. After all is said and done, run DBCC CheckDB 2 or 3 times after to verify. Keep copies, and file away any good backup prior to corruption "just in case".
Got much info about DBCC Command. Thanks.
The command dbcc checkdb repair_allow_data_loss is not working. I also read the another post from here: http://www.stellarinfo.com/blog/dbcc-chekcdb-repair-allow-data-loss-not-working/ and also found it useful.
I'm curious about this line:
"
Never assume that checks against the secondary are enough. Even with an exact replica of your primary database, there are still physical issues that can occur on the I/O subsystem of your primary that will never propagate to the secondary.
"
So far, everything I've read suggests that restoring a full backup and running CHECKDB on it is a good way to offload the performance hit – are you saying that this method is flawed? I haven't had much success in finding out exactly what could go wrong – it seems to me that if the backups are safe, so is the data. Do you have any suggestions for further reading on this?
I just mean that occasional checks on your primary are worthwhile. If your primary is connected to one SAN and the secondary is connected to another, you can catch physical issues on the primary before they become logical issues and corrupt your data. If you wait until the corruption has made it to the secondary, that might be one checkdb too late.
I'm feeling really dense right now – I must have read this a hundred times and it's not really sinking in. Would running a PHYSICAL_ONLY on primary and the full shebang on a restored-from-backup secondary cover all the bases?
Awesome! thanks for sharing valuable information
Hello! This is a great read! It's noted that "Run DBCC CHECKDB often against the full restore". Could a Full and the latest Diff work? Or does it need to be a Full backup?